Hi,
I’m struggling with setting up GPU passthrough on a new machine with a discrete GPU from AMD (RX 6800 XT, not sure the exact model matters much).
Some time ago I managed to setup GPU passthrough on an older laptop with a Nvidia Quadro T1000 Mobile, mostly by following NVIDIA GPU passthrough into Linux HVMs for CUDA applications (and the linked post by neowutran). So I tried doing the same thing on the new workstation, but I ran into some issue that I’m not sure how to solve 
Note: My goal is to use the GPU for opencl stuff - I’m fine with a VM accessible only through text console, perhaps that might simplify stuff a bit.
Anyway here’s what I did (the main/interesting parts, I don’t want to repeat all the details mentioned in the linked posts):
- list the PCI devices
dom0:06_00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] gpu_vm
dom0:06_00.1 Audio device: Advanced Micro Devices, Inc. [AMD/ATI] Navi 21 HDMI Audio [Radeon RX 6800/6800 XT / 6900 XT] gpu_vm
- add them to GRUB_CMDLINE_LINUX, rebuild grub.cfg and reboot
GRUB_CMDLINE_LINUX="… rd.qubes.hide_pci=06:00.0,06:00.1"
I did check that if I press “e” in grub, the option is there during reboot.
-
modify the stubroot, as described in one of the linked guides (AFAICS this is not entirely necessary as my machine has less than 3.5GB of RAM, but I did it anyway)
-
create a standalone VM “gpu_vm” with ~3GB of RAM / a couple CPUs, install Fedora 37
-
attach the PCI devices to the VM
qvm-pci attach -o permissive=True -o no-strict-reset=True --persistent gpu_vm dom0:06_00.0
qvm-pci attach -o permissive=True -o no-strict-reset=True --persistent gpu_vm dom0:06_00.1
(I did try this with/without the permissive/no-strict-reset flags, also from the VM settings.)
- (re)start the VM
The gpu_vm VM usually starts fine, and things seem to work to some extent - I can log-in, install and run radeontop, etc.
But there are various issues:
-
radeontop reports 100% utilization on everything, which is clearly nonsense - nothing is running
-
there seem to be strange dmesg issues in dmesg (in the VM)
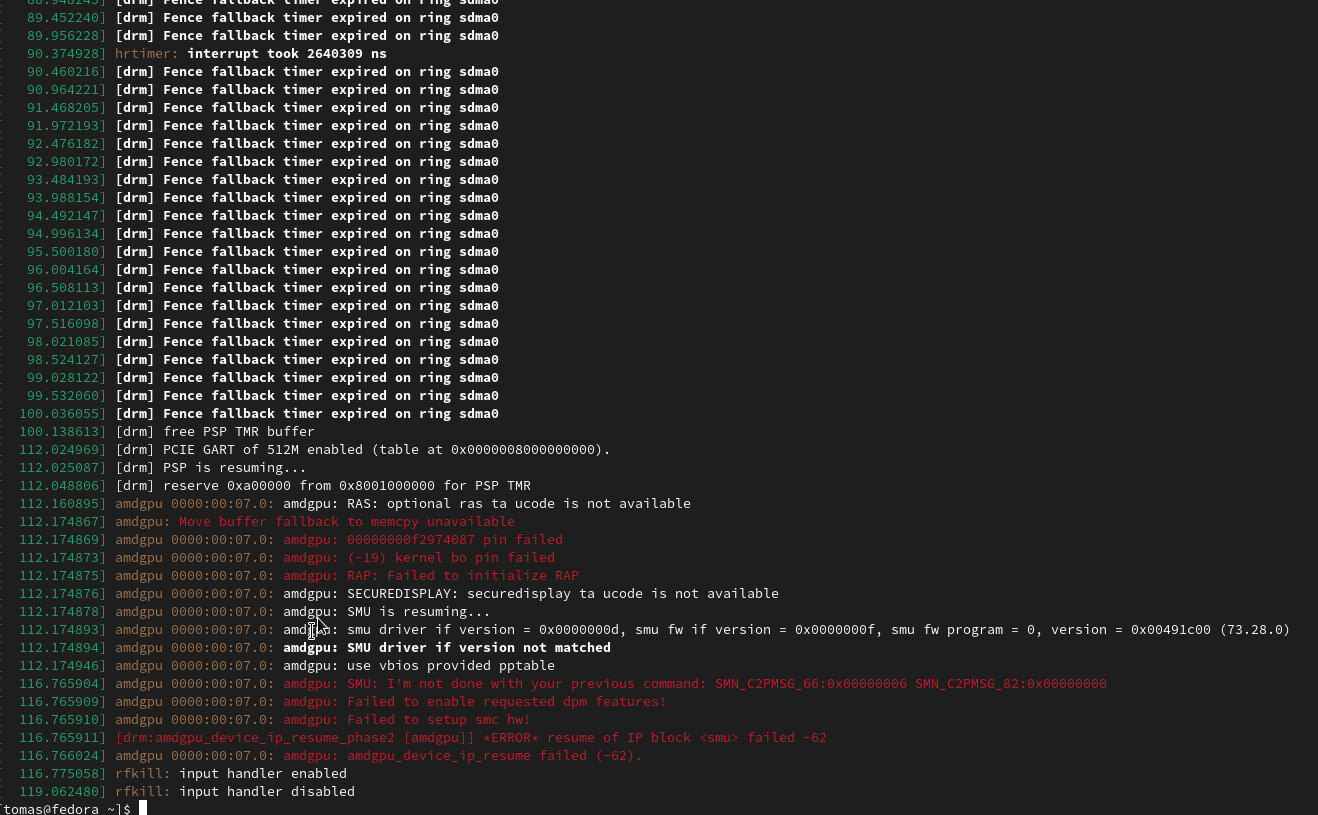
- when I restart the VM, it usually fails with a message:
Qube gpu_vm has failed to start: internal error: Unknown PCI header type '127' for device '0000:06:00.1'
and libxl-driver.log says
2022-12-31 18:20:20.608+0000: libxl: libxl_pci.c:1484:libxl__device_pci_reset: write to /sys/bus/pci/devices/0000:06:00.0/reset returned -1: Inappropriate ioctl for device
2022-12-31 18:20:20.670+0000: libxl: libxl_pci.c:1489:libxl__device_pci_reset: The kernel doesn't support reset from sysfs for PCI device 0000:06:00.1
2022-12-31 18:26:30.857+0000: libxl: libxl_pci.c:1484:libxl__device_pci_reset: write to /sys/bus/pci/devices/0000:06:00.0/reset returned -1: Inappropriate ioctl for device
2022-12-31 18:26:30.986+0000: libxl: libxl_pci.c:1489:libxl__device_pci_reset: The kernel doesn't support reset from sysfs for PCI device 0000:06:00.1
I did try different combinations of no-strict-reset/permissive, not-adding the audio part (shouldn’t be needed for opencl, I guess), but no luck.
I’m not sure what’s wrong or what to look for, so I was trying various things. For example I did notice dmesg in dom0 still says even after hiding the PCI device
[ 4.179504] [drm] amdgpu kernel modesetting enabled.
[ 4.179554] amdgpu: CRAT table not found
[ 4.179555] amdgpu: Virtual CRAT table created for CPU
[ 4.179561] amdgpu: Topology: Add CPU node
Which seems strange, so I tried blocking the amdgpu module by addning modprobe.blacklist=amdgpu. The module disappeared from dmesg, but that didn’t resolve the issue.
I also tried installing kernel-latest (6.0.12), but again no difference
So, what am I doing wrong?