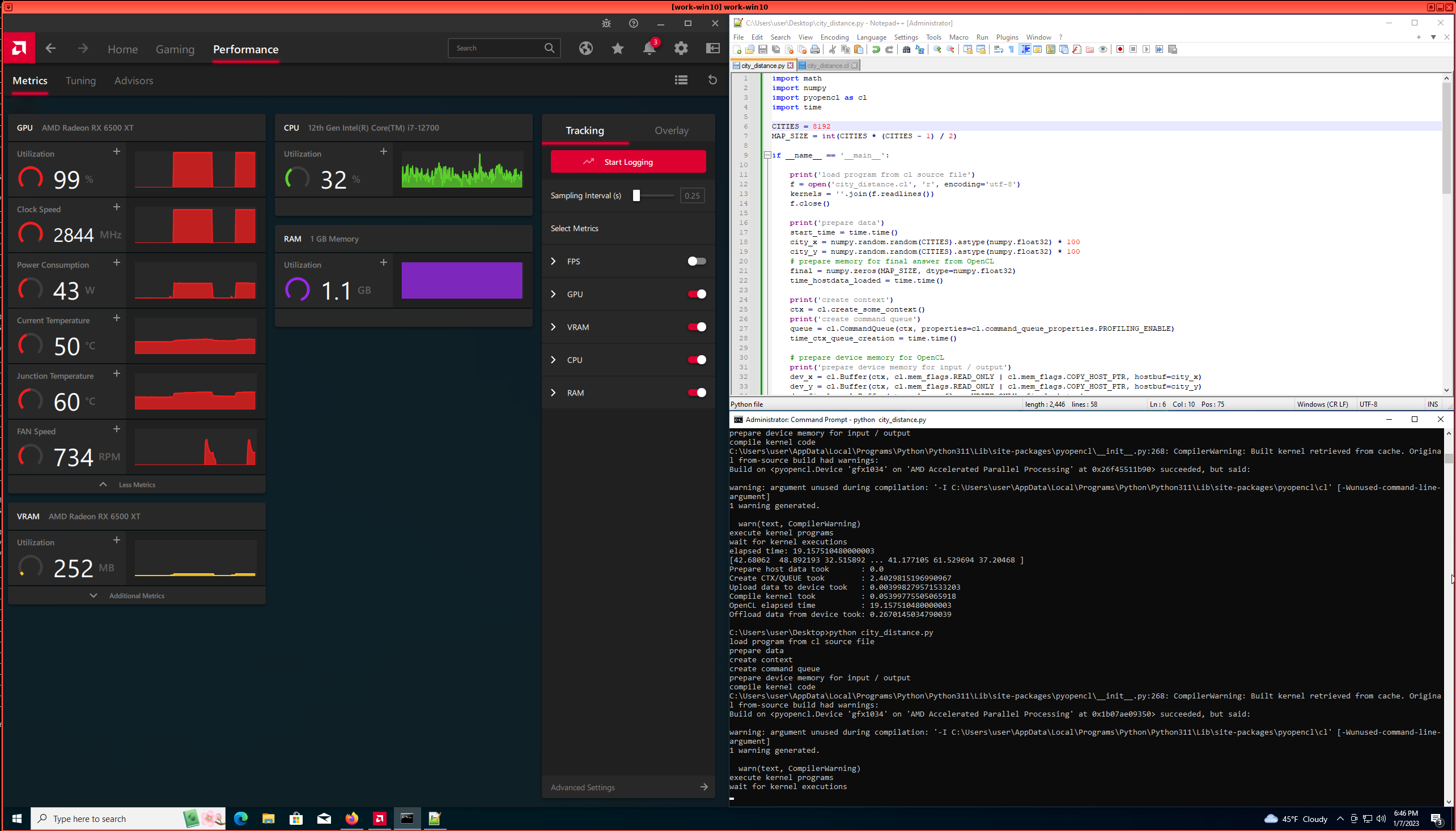
I managed to install Win10 using qvm-create-windows-qube - which is a great tool, BTW, thanks for suggesting it!
And it seems the GPU actually does work in the VM, the VM can be restarted without any PCI errors etc. I haven’t done any extensive testing - essentially just installed pyopencl, drivers from AMD and tried some simple opencl examples. And it seems to work - there are no errors, the AMD tool shows increased GPU utilization etc.
So there’s a chance this might work with a Linux VM, hopefully. This Windows experiment just reminded me why I left that world a decade ago and how used I’m to the Linux environment.
FWIW there actually was one hiccup - I tried to inrease the amount of RAM for the Windows VM, because 1GB is rather low. I ramped it up only to find the VM no longer boots, because the SeaBIOS fails with
Boot failed: could not read the boot disk
I initially thought this happened because I attached the PCI devices, but after some experimentation I figures it’s the amount of RAM configured for the VM. The exact value where it breaks is 1299MB (while 1298MB still boots). I have no idea why.
For the linux vm, can you show your boot command line ? ( “cat /proc/cmdline” inside the linux vm )
Also try to add “pci=nomsi” in the vm boot parameter.
Can try different kernel version to check if the issue is always the same ? (You can download pre compiled kernel version from fedora to check quickly )
I tried adding pci=nomsi but that didn’t change anything.
As for the kernel versions, I already did those experiments a couple days ago - I tried a couple older kernels available from fedora (5.19 and 6.0 IIRC) and then I built a couple custom kernels including 5.10, 5.15 and a bunch of others.
And I think the issues were always the same - no support for the GPU up to 5.14, and then it fails pretty much exactly the same way when loading/initializing the module (just like in the dmesg in my first post).
[Sat Jan 7 21:49:42 2023] PCI: Using host bridge windows from ACPI; if necessary, use "pci=nocrs" and report a bug
[Sat Jan 7 21:49:42 2023] PCI: Using E820 reservations for host bridge windows
[Sat Jan 7 21:49:42 2023] ACPI: Enabled 2 GPEs in block 00 to 0F
[Sat Jan 7 21:49:42 2023] ACPI: PCI Root Bridge [PCI0] (domain 0000 [bus 00-ff])
[Sat Jan 7 21:49:42 2023] acpi PNP0A03:00: _OSC: OS supports [ASPM ClockPM Segments EDR HPX-Type3]
[Sat Jan 7 21:49:42 2023] acpi PNP0A03:00: _OSC: not requesting OS control; OS requires [ExtendedConfig ASPM ClockPM MSI]
[Sat Jan 7 21:49:42 2023] acpi PNP0A03:00: fail to add MMCONFIG information, can't access extended PCI configuration space under this bridge.
[Sat Jan 7 21:49:42 2023] pci 0000:00:03.0: Video device with shadowed ROM at [mem 0x000c0000-0x000dffff]
[Sat Jan 7 21:49:42 2023] pci 0000:00:06.0: can't claim BAR 0 [mem 0x60e0000000-0x60efffffff 64bit pref]: no compatible bridge window
[Sat Jan 7 21:49:42 2023] pci 0000:00:06.0: can't claim BAR 2 [mem 0x60f2000000-0x60f21fffff 64bit pref]: no compatible bridge window
Interesting. As it’s related to “extended PCI configuration” it’s quite plausible it’s related to the issue. I wonder why it’s happening, though. I found this ([Resolved] No extended PCIe config space access - CentOS) which suggests to add memmap=, but no matter what parameters I tried I always get
Physical KASLR disabled: no suitable memory region!
Other posts that I found suggest it happens in VMs with too little memory, but I used 2GB (and even bumped it up to 4GB).
Also, I searched through the gitlab issues and there are some with very similar symptoms. E.g. this one (SMU fails to be resumed from runtime suspend (#2173) · Issues · drm / amd · GitLab) has almost the same failure. All the stuff I found was related to suspend / resume - not sure how is that related to the VM startup, but I guess it’s similar to the initialization that needs to happen on resume.
so there should be usable memory between 1M and ~2130M, so I tried memmap=64M$1M a number of similar values. No luck, and there does not seem to be anything on the console before the VM shuts down.
I tried with 8GB for this VM. Sadly, it doesn’t work, because the startup immediately fails with
Boot failed: could not read the boot disk
so I don’t even get to grub
It seems the highest value that works is 3600MB - if I go any higher, it fails. This is suspiciously close to the 3.5GB threshold mentioned in windows gaming HVM guide. But I do have the qemu-stubdom-linux-rootfs patch in place, so that shouldn’t be it.
I was wondering how come the Windows VM stopped booting at 1299MB and the Linux VM at 3601MB. I mean, it’s almost exactly twice the amount of RAM, that’s a bit suspicious. And I realized I increased the number of cpus for the Linux VM to 4, while Windows used the default 2. Which matches the 2x difference … so I bumped the number of cpus to 10, and the Linux VM booted with 8GB of RAM. I have no idea what’s causing this, though.
Anyway, no change on the GPU front - the MMCONFIG still fails, and the GPU does not work.
And if I try memmap=64M$0x100000000 (which should be usable region per dmesg), the boot fails (even with nokaslr).
For my own issues and tests, I recompiled vmm-xen-stubdom-linux to remove this patch, then modified manually the rootfs. I got different result (if my hardware is not trolling me), could be worth trying.
Yeah, the memory issue is pretty bizarre. It’s a fresh Qubes install so I’m mostly sure haven’t broken anything by messing with it. I’ll try applying the patch, worth a try.
I didn’t have time to try applying the patch, but I noticed a couple interesting thing about the memory limit issue while experimenting with the Windows VM - it only happens when the PCI devices (for the GPU) are attached.
The VM is created with 2GB of RAM, but as soon as I attach the PCI devices, it refuses to boot with more than 1198MB. If I detach the GPU devices, I can start the VM with 8GB of RAM just fine, there’s no issue with it. But as soon as I attach the PCI devices, I start getting
Boot failed: could not read the boot disk
The second interesting thing is the number of CPUs doesn’t seem to make a difference. On the Linux VM increasing the number of CPUs allowed me to use more memory, but on Windows it doesn’t seem to make any difference.
I tried rebuilding the stubdom, but that didn’t make a significant difference - the amount of RAM that I can assign to the VM increased, but only a little bit, from 1198MB to 1298MB. It’s rather suspicious the difference is exactly 100MB …
( I don’t know if it will solve nor help for your issue, but I am having some similar issue on my new hardware, and removing this helped me and changed the behavior )