This guide explains how to install text-generation-webui (oobabooga) on Qubes OS 4.2.0, it can be used with nvidia, amd, and intel arc GPUs, and/or CPU. I will only cover nvidia GPU and CPU, but the steps should be similar for the remaining GPU types.
The GPU used is the nvidia 4060, it might not be exactly the same for nvidia GPUs that use the legacy driver.
Not having a GPU is going to greatly limit the size of model you can use, and even small models are going to take relatively long to execute.
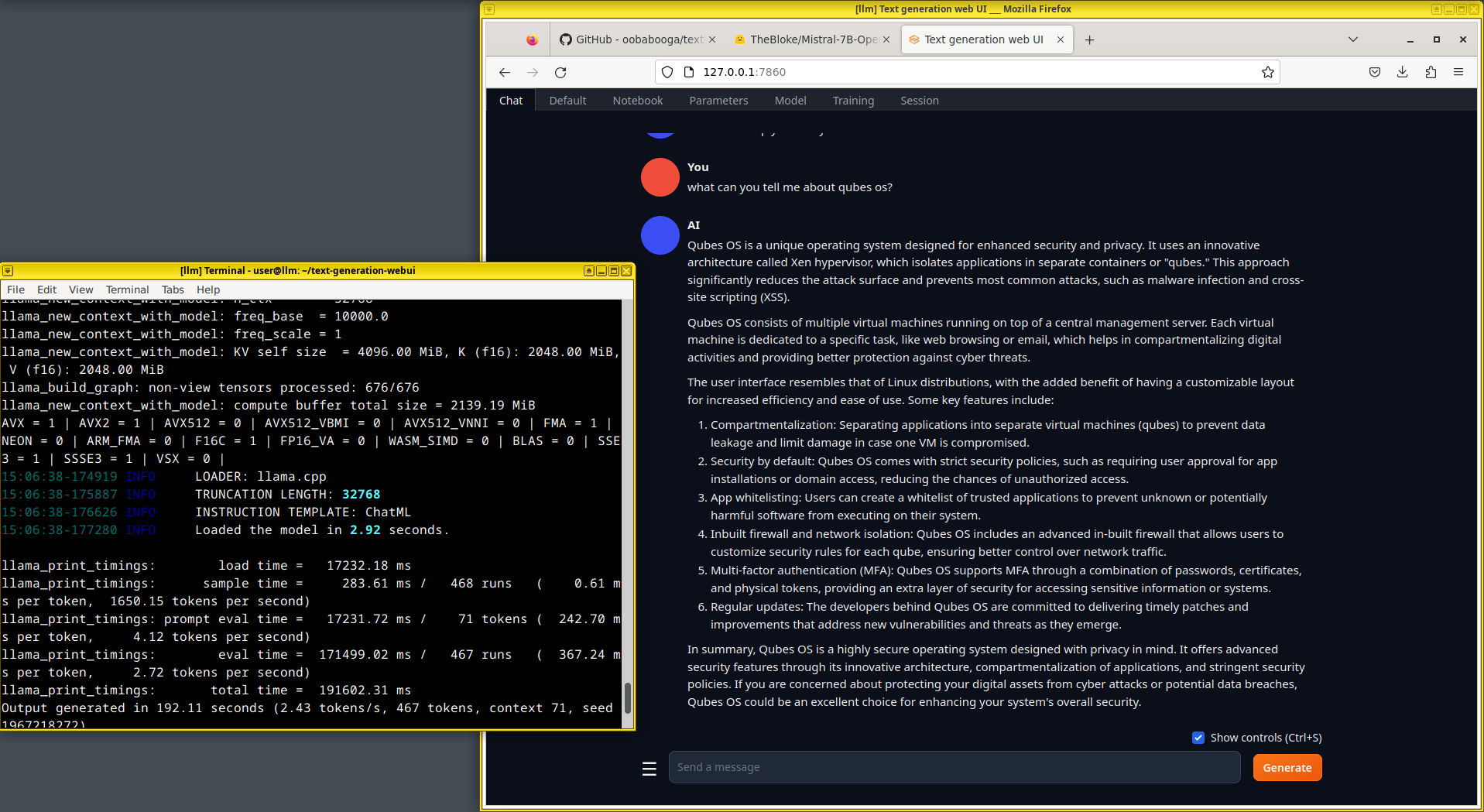
I have tested the time it takes to answer the question ‘what can you tell me about qubes os?’ with a 7B model on 3 different systems running Qubes OS:
i7-8650U (Old laptop CPU): ~200s
i9-13900K (Desktop CPU): ~45s
nvidia 4060 (GPU) with i9-13900K : >10s
Expect the number to drastically increase with the size of the model, bigger models will be practically impossible to use without a GPU.
That said, there are pretty decent 7B models, and they can run on older laptops.
Running LLMs in Qubes OS
Qubes OS isn’t the ideal platform for running LLMs, especially if you plan on running large size models. The bigger models are probably going to give you memory issues, unless you have a system with 64/128GB memory. The models also take up a lot of disk space, you might want to use NAS or DAS for storing the models you don’t currently use, to avoid have to use your Qubes OS storage pool.
If you don’t have a GPU, you can skip to installing text-generation-webui.
GPU passthrough
Follow this guide, it explains how to do passthrough: https://neowutran.ovh/qubes/articles/gaming_windows_hvm.html
I’ll only give a summary of how you configure GPU passthrough, there are already multiple guides going into detail about passthrough.
You are also only going to need CUDA support, which makes passthrough slightly easier.
- Find your device ID with lspci.
- Hide the device ID from dom0, by adding rd.qubes.hide_pci=ID to grub.
Generate grub and reboot, grub2-mkconfig -o /boot/grub2/grub.cfg - Check if the device is hidden, sudo lspci -vvn, kernel driver should be pciback.
- Use the patch_stubdom.sh script to patch qemu-stubdom-linux-rootfs
If you are having issues with passthrough, search the forum.
Installing the CUDA driver
wget https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo add-apt-repository contrib
sudo apt-get update
sudo apt-get -y install nvidia-kernel-open-dkms
sudo apt-get -y install cuda-drivers
Installing text-generation-webui
Make a qube with 16 GB memory (minimum 8 GB), and 25 GB disk space. If you are using a GPU it needs to be standalone with the kernel supplied by qube, if you used the patch script the name needs to start with gpu_, you also need to install the CUDA driver and pass the GPU.
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
./start_linux
You will be asked about your hardware, either choose your GPU or select CPU.
Let the installation complete and there should be a web server running on localhost:7860.
Testing a model
The Mistral-7B-OpenOrca-GGUF is a good test model, it should be able to run on most hardware.
cd text-generation-webui/models
wget https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/resolve/main/mistral-7b-openorca.Q4_K_M.gguf?download=true
When the file is downloaded, go back to the web interface and refresh the list in the model tab, select the model and load it. Select the CPU option, before loading, if you don’t have a GPU.
You should now be able to use the model in that chat tab.
It should look something like this