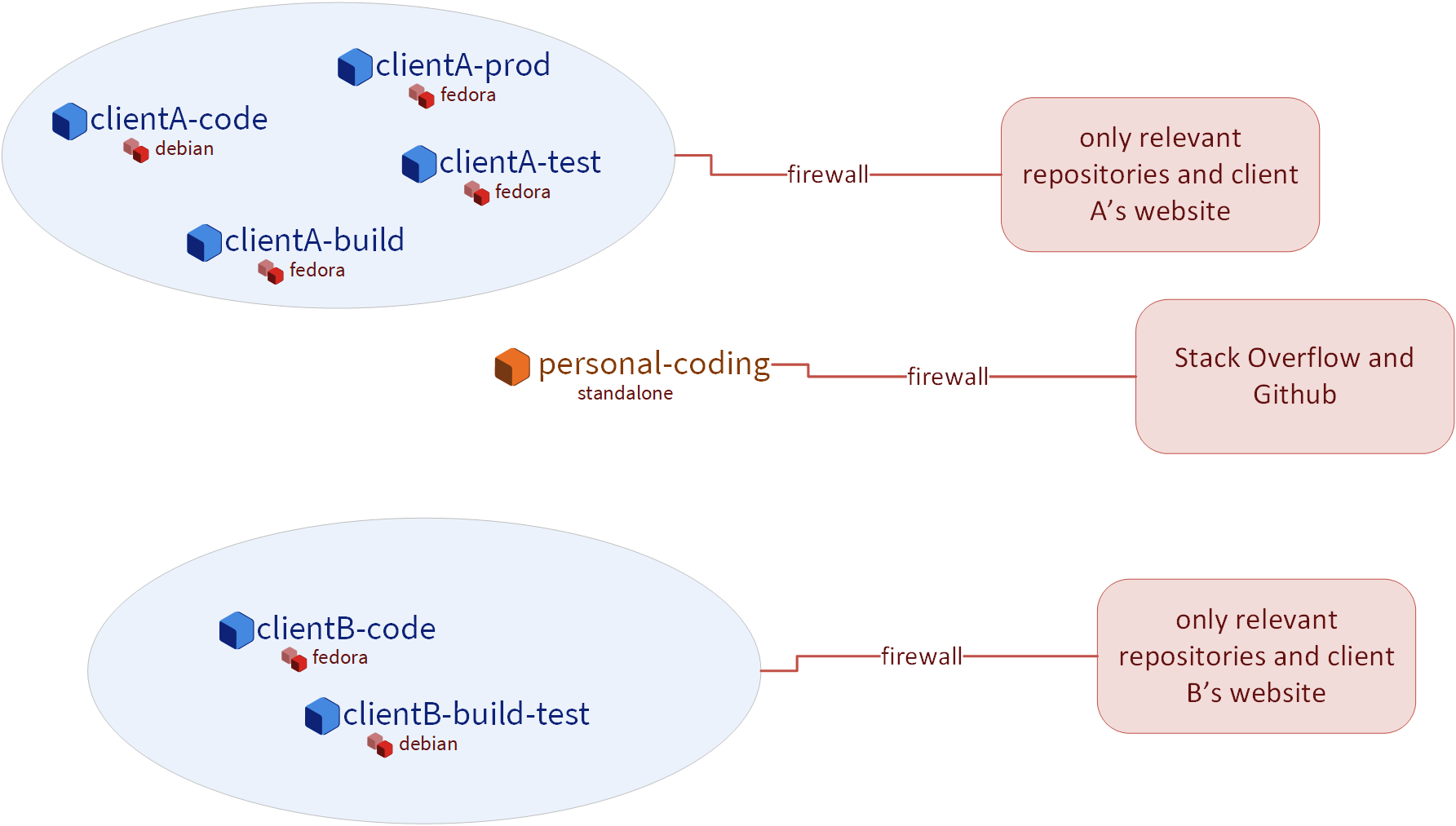
In How to organize your qubes | Qubes OS it says that Alice split the qubes twice: once per client and once per task: https://www.qubes-os.org/attachment/doc/howto_use_qubes_alice_1.png
But I don’t really get it. Why would I need to split “code” from “build” or from a “test”? If the machine is infected in one of these, the chances that the parent(the template) is infected, so why split if it’s not the individual qube’s fault?
Same goes for the installation of the software. As I understand I need to install the software either in the template or use a standalone. The last one is not really an option here, too much space/work for each qube(correct me if I’m wrong). And if I install the software in the template, say vscode or something alike(that I can’t be 100% sure it’s safe and won’t have any malicious package/code) then I will infect all the qubes that are based on it, right?
Also, where do I install docker. If it’s gonna live in the template space, then it’s too risky, because I can’t be sure 100% what docker-images are etc.
I’m very confused on this and hope you guys will make it crystal clear to me what I can do about all this and navigate me in the right direction.
I’ll try to be as short as possible. Malicious code gets malicious only when built/run. So, until you built/run it, you can even keep it in dom0. That is why you use disposable test qubes to built and in another to run it.
Same for installation.
Can you please maybe be as explanatory as possible, because it’s very hard to understand what may lay behind your words for a newbie as I and it makes it even more confusing for me atm, tbh.
Malicious code may lay in many areas(as I mentioned previously), IDE addon, docker etc. I don’t want to repeat everything I said just a post ago, but “So, until you built/run it, you can even keep it in dom0.” doesn’t really address the issues I pointed out at all it even contradict to the underline principle upon this system is designed.
OK, it is quite possible that I don’t understand your question, too, so I’ll try with even more banal, real life analogy example.
Say you have a rat poison in a bottle. If you don’t “run” it, you can even keep it in your fridge (dom0, template), it won’t poison your food right?
But when you “run” it in your basement (test qube) and lock your basement, it gets poisoning for the rats, as well as for almost any other being as well. But it is poisoning only in the basement…
That is for “running” it. For “built” the analogy is getting compounds for rat poison you wanna make. It is safe to make the poison, only in safe environment - laboratory, again isolated “test qube”.
If this doesn’t make good enough, probably some other will jump in with better explanation.
This is probably not explained with the level of detail that you’re asking, but I believe the topic addresses some of the questions you have and can be a starting point (correct me if I’m wrong, and don’t hesitate to ask further clarifications!)
Note: I linked to my own post because I remember precisely what I wrote in it, but I believe you may find the entire thread interesting.
My experience as a teacher is when basics aren’t comprehended (when is that malicious code can make a damage) then any sufficient explanation can’t help either. On the contrary usually brings further confusion.
It’s not about the tool here, or the way how something to be done. It’s about what.
Let’s see where this will evolve…
It’s just an example, you could also just do everything in a single development qube.
Qubes OS gives you the freedom to make your compartments the size that fits you, it can be per task or per domain, or some other logic group that fits your workflow.
OK, so I thought I may infect the system while unpacking/installing inside the template and apparently that is not the case, unless I execute/run it by myself afterwards and taking into account what @unman said in https://forum.qubes-os.org/t/how-to-create-template-vm-for-custom-software/17862/12: " Chaining in this way might allow for privilege escalation or data
extraction that would not be possible if the other application were
not installed, even though you have not run it in that qube."
@gonzalo-bulnes thanks for bringing this out, the question of this topic was the same question I had in my head with all of these and tbh, this doesn’t yet add up, because using separated template just to run one app is kinda cumbersome, but I guess there’s no good alternatives to this.
The example with storage qube from the above mentioned topic is very rational, but how in practice does it look like? Do I send each file from one AppVM to another? Are there any other, more practical ways to deal with this?
Also, if we take the software example, each time I want to create a qube for a client I need to install and reapply all my settings for my soft. Because if I install VSCode in the template and then run VSCode on AppVM-1 and AppVM-2 they have fresh installs.
Also, If I want to run the code, I need to copy it to another AppVM just to see the changes?
@renehoj You’re talking about standalones, right? My problem with this is the space each of them take and no option for further re-use. They obviously have relevancy, but not in this case.
TL;DR: There are often trade-offs involved in setting up your system and workflows in one way or another, and a setup that’s right for me might not be right for you. I’ve found that starting by defining my threat model (or risk profile) is a useful way to reduce the number of options I have to consider when making decisions that affect either my system or my workflows and ultimatey decide how much time or convenience I am willing to invest in mitigating a given risk.
The short answer is yes, if you want two (or more) qubes to be isolated from each other, you’ll copy any files and configuration that you want to be present in both. The longer answer is: that doesn’t mean the process has to be tedious and there are a number of ways in which you can make it more manageable.
For example:
You can hold some configuration files in the template and have those be copied automatically as part of the normal appVM operation. (A large portion of the file system of any appVM is copied from its templateVM when the appVM starts, e.g. any file in /etc. See docs quoted/linked in this post for details.)
Depending on your use case (e.g. a new customer/client since you mention that) you could have an appVM that is fully configured but that you don’t use directly. When you start working for a new client, you clone that appVM. (And presumably, once the work is done you could destroy that clone to ensure you don’t retain unnecessary client/customer data.) It really depends on your work and needs, but it’s an option that may fit some scenarios.
It may also make sense to invest some time automating the creation or configuratiom of some qubes. For example, you may notice that it is possible to create sys-usb in a semi-automated fashion, by running a single
command. (This is really just an example, but the command is in this section of the docs). Depending on their needs and abilities some folks automate the creation or configuration of qubes in a similar way, using a number of different tools. (That is a whole topic in itself.)
You may have noticed that I keep saying: depending on your use case, depending on your needs, depending on the abilities or time you have… it’s not a coincidence. There is rarely one true way of doing things, and most decisions end up uncovering one or more trade-offs. You’ll often see recommended to start your reflection by listing what you want to protect, from whom, why, and how important that is. (That process is sometimes called creating a threat model or a risk profile.)
Such an exercise is often a good way to determine how much effort (time, storage, appVMs, you name it…) it makes sense for you to dedicate to mitigate which risks. Not everything that someone else does is necessarily useful or desirable for you to do.
As food for thought, since you ask about copying files from one qube to another, notice that the operations that you may want to allow or restrict could end up being direct opposites depending on what you want to protect! For example, the requirements of ensuring the integrity of some data or ensuring its confidentiality typically lead to opposite rules for copying data from one qube/domain//level to another. (The rules around copying data that you’ll find in the Qubes OS docs are typically about ensuring data integrity: “never copy data from a less trusted qube to a more trusted qube” —this post made me realize that— trusted in that case means something along the lines of “I trust this qube doesn’t contain malware”.)
It might sound counter-intuitive, but keeping confidential data in a qube ridden with malware may not be much of a problem if you can ensure such malware cannot get the data out of the qube. That’s very much the principle behind the idea of the so-called “air gap”, and one possible use for a vault qube. (But then you would certainly not copy anything from that vault to, for example, dom0 because data integrity matters a lot in dom0.)
Always keep in mind that you are the one assigning meaning to qubes, colors, etc. You decide which data you store in which qube, and why.
In my experience, reflecting about my goals is how I go from thinking about all the setup I could do if I had an infinite amount of time, to the setup that I will find useful tomorrow morning. Additionally, I’ve found that you’ve got a good chance of getting useful answers in this forum when asking how to achieve a specific goal with the tools available in Qubes OS
Much appreciate such a detailed answer. Noted for myself lots of things.
Just to sum it up regarding soft installation for the Alice’s example: I can use a template to install soft, then I can create my clone-to-be AppVM with configured settings, addons needed, docker images etc(because I will be exposed to the same addons/docker images in other AppVMs, even if I won’t use the clone-method), and then clone that AppVM when I need to create a new one.
Is this a good approach with a threat model of security above everything else?
Saying “a threat model of security above everything else” doesn’t say much, but let’s look into what such a workflow would give you. (If you want to learn about creating a threat model, I linked a guide from the Electronic Frontier Foundation in this post.)
You’ll create a templateVM (by cloning one of the official ones, or use one of the official ones directly).
You’ll install software in it. (You mentioned VS Code above, note that it may be a little difficult to follow the official VS Code installation instructions in a templateVM, because the templateVMs are offline by design. If you don’t care about the Miscrosoft-specific bits, you can install VS Codium —the open-source core of VS Code— easily because Debian and RPM packages exist. Worth a look IMHO: https://vscodium.com)
You’ll then configure your apps in an appVM. That appVM will be presumably online since you want to download some Docker/OCI containers to it. In the compartimentalization spirit, you’ll probably restrict the network usage to the minimum to get what you want (e.g. download containers using Docker, but probably not browsing the web).
Then you’ll clone that appVM for each new project/client/need.
What does that give you in comparison with a traditional Linux installation?
Most of the filesystem is copied from the templateVM, so malicious modifications to, say, /usr/bin/example won’t persist after you reboot your appVMs.
All the clones will share whatever you did in the original appVM (until the moment you cloned it), but nothing you do in a clone will affect the other. That means that the data related to project/client/need A will be properly isolated from the data related to project/client/need B. (Same goes with, for example, malware that found its way through the activities related to project/client/need A and B, for example by browsing to a malicious website.)
Is that good? Does that address concerns you have when working on A and B? Only you can decide that, but as such, it is something that wouldn’t be that easy to achieve with a traditional Linux installation.
Thank you so much, this is so helpful. I didn’t know VSCode has an OSS alternative, thanks for sharing.
Yes, that pretty much answer my concerns I think, will use that approach.
{kind=link}